

I recently attended the JAX London 2015 conference, held at the Business Design Centre in Islington, London. It’s a tech conference, focused on Java for software engineers and business professionals, with workshops and talks from some of the leading companies in the industry.

I’ve attended JAX before in 2011 and 2012 – back when the ‘hot’ new topics in the industry were ‘Big Data’, ‘The Cloud’ and Mobile. I picked up a lot of great info at those conferences, and spent the next few years continuing to work as a consultant on client sites during the day, while also developing my own mobile/cloud applications in my spare time (which took up most of any spare time I had).
Keeping one eye on what was going on in the Industry – you could see that among the chatter and chaos of the new and shiny – certain new trends were emerging that you could tell were gaining some traction. Building on developments in the Cloud over the last few years – DevOps, Containers and Microservices definitely looked to be up and coming, disruptive hot topics.

DevOps isn’t all that new – the first I heard of it was in a session at JAX London in 2012 JAX London 2012: Devops with the S for Sharing – but at the time I didn’t really see how it affected me directly as a developer (I was more interested in the mobile and cloud talks at the time). Fast forward 3 years – and you can see DevOps concepts starting to creep into companies I’ve worked for. Led mainly by devs with an interest in tech and a visions for a better deployment – rather than edicts from the business – it’s still in its early days, but definitely looks to be here to stay. I’ve noticed Microservices too are starting to be talked about more, and ‘Cloud’ usage, of course, continues to grow (I haven’t seen containers used in the wild as yet – but I’m sure it’s just a matter of time).
So with all this in mind – I thought it seemed like a prime time to start to learn more about all this – both for my professional career, and also for the side projects I work on.

There are a bewildering selection of tools and choices out there – and it’s difficult to know where to start, and what to focus on. I find attending a conference like JAX is a great way to quickly cut through the chaff, and get to the core of what they key topics and tools are likely to be over the next few years. Just by attending the sessions you can usually pick out common threads that crop up time and time again – and the ones that are worth diving deeper on.
With that in mind – I thought I’d scan through my conference notes (while it was still fresh in my head) – and jot down what some of my key takeaways from the conference were. I was going to a top 10 list – but when I wrote them out – it turned into a top 15 instead.
Caveats – I’m a dev, I couldn’t attend all the sessions I wanted to, and I can’t remember everything from those I did – so this is just what I personally found particularly interesting, recorded here for posterity.
1. The Business Landscape is Changing

Business is changing. We are shifting into a post-industrial society where economic activity become more driven by the delivery of services rather than products. Technological developments are breaking down old boundaries that existed between the online/offline, and business/social worlds. Everything is becoming more complex, faster changing, and boundaries are becoming more fluid – an example Jeff gave was in the future – if you have problems with the music system in your car – who do you turn to – Honda, Spotify, your ISP?
Companies need to think about how they can navigate this complexity in these increasing changing times. The old sausage machine approach to service delivery doesn’t cut it anymore with increasingly sophisticated customers. Companies need to build transparent and long term relationships with their customers, be empathetic, and respond quickly and usefully to meet their changing requirements.
How to do this?
- Design for delivering the services first (software second)
- See everything as a service – both internally and externally
- Minimize latency, maximise feedback
- Respond to change quickly (and appropriately – get feedback to check your response was a good one, and if not be able to change it quickly)
- Constantly look to improve relationships with customers, and internally – break down silos – dev and ops need to act together
- Design for failure
- Just about everything has a software component these days – this adds complexity and brittleness
- If failure is unavoidable, don’t try and fix it completely – look at handling it gracefully. Cause it to happen, prod it and learn how every system and person responds to it
From Sacha Labourey‘s (CloudBees) keynote: ‘From 1 RPM to 1,000 RPM – Succeeding in a Software-Defined Economy’

Sacha reiterated what Jeff said about business landscape is changing, and companies need new ways to differentiate themselves in this increasingly complex and fluid environment.
Lots of efficiencies have been made in the last 15 years on how software is developed – Agile – scrum/kanban/xp has led us to be able to create software pretty efficiently to support the business – ‘IT is *for* Business’.
However, the difficulties and friction between the development and operations teams have meant that despite all the efficiencies – business change can only be implemented at the speed of this weakest link, making many of the new efficiencies irrelevant.
This is what needs to change, and what is changing now. Software has been becoming more and more core and more pervasive, to the point where it is now as much part of the business as anything else, now ‘IT *is* Business’.
DevOps is key to removing this friction between development and operations. It’s key to get the business onboard with this. The steps to get business buy-in are:
- Embrace Continuous Integration (CI)
- Embrace DevOps and Continuous Deployment (CD)
- Educate the Business
- Start With Small, Achievable Projects
- Advertise Your Wins
2. DevOps – Crossing the Streams
From Vinita Rathi‘s (Systango) session: ‘DevOps, what should you decide, when, why & how?’

DevOps is blurring the traditional roles between Development and Operations – to remove the friction in getting new developments in production environments quickly. It’s not necessary to deploy frequently, but you need to be able to deploy easily, and quickly when you need to (and have confidence that your changes will work, or if not you can rectify them quickly).
In a nutshell it involves:
- Continuous Delivery (see #3 below)
- Measurement – to check that what you are delivering works, and meets requirements (see #4 below)
- Automate as much as you can (see #5 below)
The bare minimum needed to do DevOps (from Vinita’s experience with Systango):
- Make deployments ‘business as usual’
- Make everyone a deployment engineer
- Strengthen the safety new with automated testing
- Be strict with version control (and vc everything – code, data and config)
- Peer code reviews
- Implement end to end performance monitoring and metrics
What tools to use?
There are a bewildering array of tool and platform choices out there to help with DevOps. HashiCorp have produced a diagram helping to categorise and group them into different stacks (see below). A fuller explanation of this can be found at http://thenewstack.io/devops-landscape-2015-the-race-to-the-management-layer/.
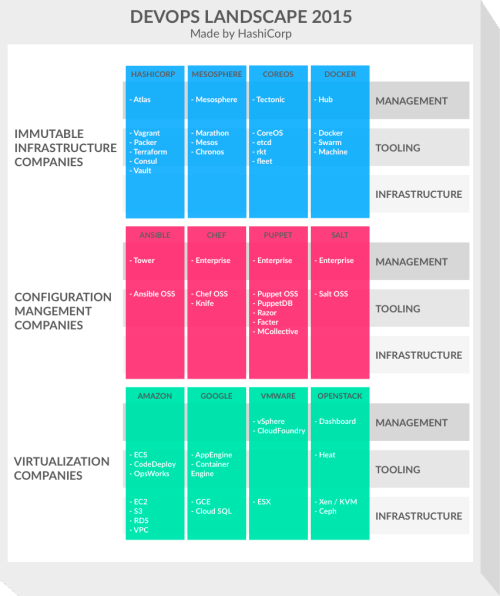
Steve and Daniel also touched on the cultural side of DevOps ‘sharing is caring’. Creating a climate for learning within an organisation and a culture which promotes job satisfaction – creating a win-win situation between dev and ops.
They reference the benefits to an organisation from following this approach – as outlined in the
2015 State of DevOps report (PuppetLabs):
- Lean management and continuous delivery practices create the conditions for delivering value faster, sustainably.
- High-performing IT organizations experience 60X fewer failures and recover from failure 168X faster than their lower-performing peers. They also deploy 30X more frequently with 200X shorter lead times.
- High performance is achievable no matter if your apps are greenfield, brownfield or legacy.
3. Continuous Delivery – Deploy Fast, Fail Fast, Fix Fast

Lyndsay looked at the 2 different teams, one maintaining a monolithic .NET legacy code, and the other developing a greenfield, modern, microservice based application. Both of these successfully implement Continuous Delivery.
He described 5 best practices common to both teams, along with 2 common pain points.
Best Practices:
- A healthy CI (Continous Integration) system
- Keep all builds green – don’t suffer red ones, even if they are red for a specific reason. Red builds can have an insidious effect on the perception of devs. Fix them or remove them.
- Testing as an activity, not a phase
- Think about testing throughout the process – how can success be measured at all stages
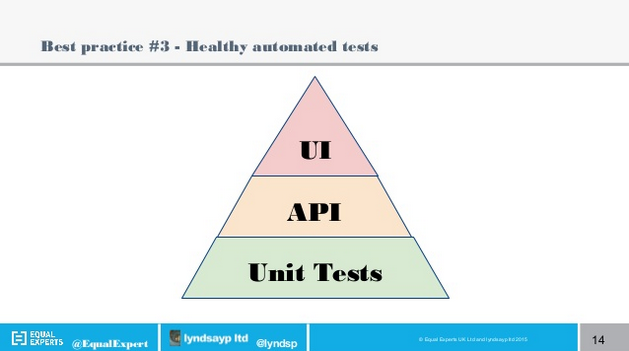
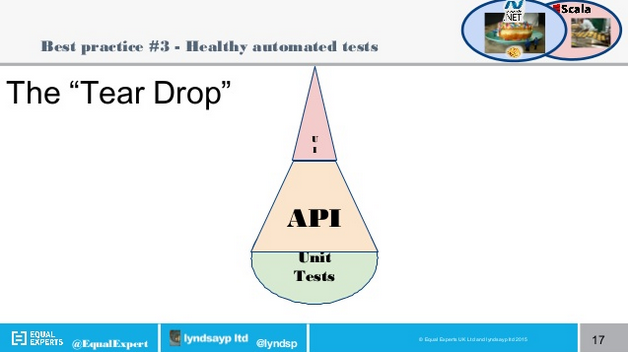
- Think about the balance between Unit, UI and API/Integration Tests (Pyramid, Hourglass, Ice Cream Cone and Teardrop distributions)
- Teardrop is best – very little UI, more API and Unit Tests
- Metrics, monitoring and reporting
- You need to know if a change deployed to production worked
Pain Points:
- Zero down-time releases
- These were difficult to achieve and needed careful planning
- Manual deployment steps
- Which leads onto..
4. Automate Everything

A key point that crops up with DevOps and Continuous Deployment is that everything should be automated as much as possible – a ‘Programmable Infrastructure’
This is important for 2 reasons:
- It ensures that deployments are consistent and reproducible
- there is less chance of user error
- the scripts and config can be version controlled
- It makes it easy to do
- If it’s easy to do – we wont be scared to do it
- It can all be automated
As programmers, we can leverage this programmable infrastructure to add value to creating the kind of scripts that a lot of ops already do. This can make ops nervous – if they have to start working with this kind of tooling more – will they become devs? (if not will devs take over their role?)
In terms of tech – Steve and Daniel recommended Golang/Python for tooling, Mesos, Kubernetes, Nomad for clustering and scheduling, networking skills and multi-cloud (don’t rely on a single could provider – even Amazon can go down).
5. Measure Everything
From Aysylu (Google) Greenberg‘s session: ‘Benchmarking: You’re Doing It Wrong’
Aysylu’s session covered Benchmarking in some detail – from the starting point of challenging everything you think you know about performance benchmarking.
Good benchmarks should test the full stack – machine code, os, networking and user utilisation (even device physics – depending on how deep down the rabbit hole you want to go..).
The key points to bear in mind when designing a good benchmark are:
- Avoid premature optimisation (‘the root of all evil’, according to Knuth) – can’t predict where bottlenecks will occur as a system grows
- Don’t use unrepresentative workloads – don’t test on a different setup to live, don’t test unrepresentative user actions (e.g. testing a cache with an even distribution, when in reality 10% of cache items may get accessed 90% of the time)
- Be aware of memory pressures – good idea to force garbage collection (GC) after the benchmark has done its setup, and again run a GC at the end and include in the BM result – it can help identify the memory footprint of the app
- Be aware of hidden components – e.g. load balancers, which can introduce latency and hurt throughput
- Be able to reproduce your measurements
- Outliers can carry more information than other data – especially when investigation performance issues
6. Test Everything (to various degrees)
If you’re doing Continuous Deployment – good automated tests are critical to ensure that nothing broken gets released into production.
As mentioned above – ensure all tests in the Continuous Integration system are green – don’t be tempted to leave red tests around (e.g. if they are not important, or if you plan to fix later). Fix them or remove them. A fully green build focuses the mind so if a red build crops up – everyone notices it immediately.
This is the classic Pyramid view on how much automated tests should be written – loads of Unit Tests, less API tests, and fewer (but still a decent percentage) of UI tests.
From Lyndsay’s experience – this (supposed) antipattern of a Tear Drop shape actually worked out better. The bulf of the tests being API/Integration tests, with minimal UI tests. Unit Tests tended to test aggregations of functionality.
7. Log Everything (that can help fix issues)
As Steve points our – debugging in containers can be a pain. If everything is in containers in the cloud – you should assume that you will never be able to attach a remote debugger to a failing app. All problems must be resolved by replicating locally and in logs.
Failures during startup/deployment can be particularly painful.
Learn to love logs, dumps and traces. Bake good logging into your app – you’ll be grateful when it’s in the cloud somewhere, having a moment.
8. Containers – Here To Stay
It’s 2015 and containers (like Docker) are mainstream and here to stay (orchestration platforms are where the action is now, e.g. Kubernetes, and the container bolt-ons are evolving).
From Ray Tsang‘s (Google) session: ‘Java-based microservices, containers, Kubernetes – how to’

Ray gave a great introduction to Containers using Docker and Kubernetes.
In the ‘old’ days we used to use shared machines to run multiple applications. They had no isolation, no namespacing, shared common libs (and had classpath configuration issues) and were generally highly coupled.
Along came Virtual Machines (VMs) which resolved some of these issues – but still had their own problems – they were expensive and inefficient (need to run a hypervisor and full OS), still highly coupled to guest OS, and hard to manage.
The new way is to use containers. These have no VM behind the scenes (no boot required – it just starts as a process, share the same kernel space and memory, but isolated in terms of resources available – which can be throttled).
Ray then went on to introduce Kubernetes – which is a container orchestration tool developed by Google initially (from their Borg internal software), but now is developed in partnership with Pivotal, IBM, VMWare, Microsoft, HP, RedHat and others.
Kubernetes introduces the following concepts:
- Pods
- Collection of containers acting as a single atomic unit and managed by kubernetes
- Labels
- Name/Value pair used to identify pods, and other, resources
- Replication Controller
- Can start up as many pods as required by the configuration template
- Will make sure they are up and running and will spin up new pods if any go offline
- Services
- Used as a connection point to access pods by clients (which use ephemeral IP addresses)
9. Microservices – Breaking Up The Monolith
Turn apps into small independent highly decoupled, modular services
Whats the problem? Well, conventional apps can suffer when they scale and move to the cloud
- Start with a simple app and database
- As it starts to scale – things like load balancers and multiple apps servers – are introduced – the ops guys traditionally help with this
- As it scales up more – more app servers are added, databases are replicated, and it starts to get more hairy
- Business then asks for some bits to go into the cloud – which turns out to be really difficult – as all components are tightly coupled together
- Have to go ahead and update something then – Boom! Major impact – because the system has scaled beyond its means
This is what micro services is trying to help with.
From Ray Tsang‘s (Google) session: ‘Writing a Kubernetes Autoscaler with Groovy and Spring Boot’

Ray gave a demo which was an extension to his introduction to Kubernetes – showing a custom built autoscaler running Infinispan distributed cache pods in Kubernetes. A very visual demo – it showed how Kubernetes could be configured through it’s template and automatically drop and create instances automatically.
Although this was a custom written demo program, Kubernetes now has native autoscaling (vertical and horizontal) built into the roadmap – probably coming in 1.1.
10. Event Sourcing – Data Integrity in a Microservice Architecture is Hard
From Chris Richardson‘s (Chris Richardson Consulting, Inc.) session: ‘Events on the outside, on the inside and at the core’

Chris looked at events outside and inside applications in the ‘Event Driven Enteprise’.
On the outside there are different options to receive events – from outside the firewall using Polling (Http, AtomPub), WebSockets, WebHooks, Twilio (and similar), and inside the firewall using standard Message Brokers (Rabbit, Kafka, ActiveMQ, etc) following standard publish/subscribe Enterprise Integration Patterns.
Event driven architectures *inside* apps introduced some new concepts- especially when those apps are Microservice based.
Although Microservices offer solutions to problems for apps in terms of scalability and maintainability, they also introduce a bundle of new issues to consider. Key among these is the problem of maintaining data consistency across different databases.
There are a number of approaches to this:
- Two phase commit – this may not be an option if using NoSQL
- Tail transaction log – turn database transactions into events – but this is low level and database specific
- Database triggers – again database specific, need a database that supports them, and need to make sure you write them
- Application code – may not work for all NoSQL databases, error prone
All of these have some issues. Chris’ solution is to put events at the core of the application using Event Sourcing. This means that events themselves become first class citizens (e.g. OrderCreated, OrderShipped) – and the events are persisted, rather than just the current state (e.g. Order). Current state can be rebuilt by just replaying the events.
This approach solves data consistency issues, gives reliable event publishing and preserves history. However, it also can create a historical record of bad design choices, can have problems handling duplicates and the event store only really support Primary Key type lookups (relies on denormalised data).
I think there is something there, and that it could be useful in specific use cases – but the approach seemed to raise more questions than it answered (for me, at least). However, if Microservices are going to be a ‘thing’ – we need methods to ensure data consistency – and perhaps the Event Sourcing approach has some of the answers and its approach will become more commonplace. For me, at least, I would definitely need to give it more thought.
11. Don’t Ignore Compliance and Security
In the brave new world of DevOps – developers can start to take control of all aspects of getting code into production. This could be a process that touches on a lot of tools and layers –
- Cloud – docker, openstack
- Config, Infrastructure as code – check, puppet
- Apps – docker images
- Deployment – continuous availablity – kubernetes
- Pipeline – git, jenkins
This opens up a potential can of worms for a dev:
- Do you know where your data is? There are laws you could fall foul of if you don’t understand. People can go to jail for this.
- Are your services secure?
- Is your docker container secure?
- Are you up to date with fixes?
- Can you prove all of this?
Steve’s advice is that this is difficult – and you need to know this issue exists, and it is difficult. Talk to the ops guys – they have more experience in this area – be aware that this is an issue you need to think about.
12. The Economies of the Cloud *Will* Impact Design

Cloud computing is real – businesses are putting money into it. It provides many benefits to business – minimal upfront investment, with ultimate scalability – put your code on someone else’s machine, and pay only for what you use.
Sounds great.
However, ‘with every tap, comes a meter’.
Now this means that hardware costs, which uses to be CAPEx are now an operational expense. Everything in the software development lifecycle is now measurable. As these costs become more transparent to the business – there will be an inevitable pressure to drive them down.
Costs for cloud are typically RAM based and measured in GB/hr. If you get charged by memory – the drive will be to optimise on memory. So the pressure will be to reduce RAM footprint while maintaining performance.
Java has been optimised for monolithic applications for a long time – the JVM developers now need to think of a different way to optimise Java for a micro services/cloud based environment. There are a number of things to consider now for this:
- Java 9 will introduce modularity
- Optimise caches – think about what you are caching an the benefits it is giving you vs memory cost in the cloud
- Reduce dependencies – think about what 3rd party libraries (and transitory dependencies) you are bundling
- Startup times are important – if you are adding/removing nodes – how long do you want to wait for it to be available?

If we are running in a container – do we even need a JVM anymore? Chris’ view was yes – JIT compilation is baked into the JVM, and with Linker coming on Java 9 Java does have a future in this environment – it all depends whether we take the red, or blue pill…
13. Don’t Fret Over Javascript
From Geertjan Wielenga‘s (Oracle) session: ‘Coding for Desktop and Mobile with HTML5 and Java EE 7’
Just like containers, devops and continuous delivery – there are of course a bewildering number of Javascript frameworks out there. Just in the last 3 years I’ve worked with clients who have used Dojo, Knockout.js and Angular.js for their client code.
It was interesting to hear Geertjan go through these (and the many, many more..) and the different approaches to choosing a framework or a library.
I think the main take aways from it for me were that Angular has such a huge market share at the moment – it looks like safe choice for any new development (if you don’t mind going the framework approach), and that, to some extent, it doesn’t really matter. Javascript clients can have such a short lifespan (1-2 years) – that whatever you choose will be around during that time, and when it comes to make major modifications – it can most likely be completely rewritten in whatever the framework of choice is then (WONTA – Write Once, Never Touch Again).
14. Java 8 – Super-Powered Interfaces
From Stephen Colebourne‘s (OpenGamma) session: ‘Java 8 best practices’

Java 8 is something I haven’t really had chance to play around with too much yet (but know I need to). I haven’t used it commercially in a consulting role yet, and frankly – it’s not highest on my priority list to go though at home just yet.
Lambdas are obviously the biggest change – and although I’ve read through examples I need to sit down and do some coding to get them to really sink in. I was aware of other changes in Java 8 – but that had always been the one front and centre.
It was great to get a best practices overview by Stephen. It was also interesting on his take on it that Lambdas were not the most important change in his opinion. The stuff that Lambdas help with is the algorithms that are hidden inside methods. You don’t have to use Lambdas – they are just a more elegant solution to a doing things that you can already do in Java 7 (and earlier). I think this is partly why I’ve felt no great urgency to learn them.
However – his view on the changes to interface was much more interesting – they’ve been given super powers! I think this is something that will have a wider impact on how code is structured – and something that I think I will need to understand fully as a priority. So Java 8 is back near the top of the learning list again!
15. And Finally..
To my most important take away from JAX London 2015 (courtesy of CloudBees)…
